Each organization in the global community of Crossref members (that’s currently over 24k organizations in 166 different countries) plays a key role in building the Research Nexus. Any opportunity we have to meet with our members in person is a highlight and a way for us to learn more from each other. The month of January saw three of us travel to Bangkok to attend the first-ever Charleston Conference organised in Asia and to meet with our growing community in Thailand.
This year, we placed a spotlight on the Latin American community, hosting the second Crossref Metadata Sprint in São Paulo, Brazil from 4 - 6 March 2026. In our first tri-lingual event, we brought together 31 participants from Argentina, Brazil, Colombia, Ecuador, and Mexico. Our goal was to foster community co-creation using the open scholarly metadata. The Sprint was an opportunity to pose questions, share ideas, collaborate on research, and propose innovative solutions that enhance the use of metadata in scholarly communication and beyond.
Read on for more details about the content of the Sprint, and the resulting projects. You can also register to join our Sprint Showcase call on 22nd April to hear directly from the team about their creations.
On 17 March 2026, we experienced an outage that affected DOI resolution for Crossref DOIs and the deposit of metadata records by Crossref members. In this summary, we outline what happened, the impact on our community, and the steps we are taking to strengthen our systems and processes as a result.
We’re excited to announce a new data citation API endpoint and are seeking your feedback. The new service makes existing data citation relationships in our metadata available, thereby surfacing this part of the research nexus. At the same time, we’ve decided that it’s time to move on from Event Data.
In 2022, we flagged up some changes to Similarity Check, which were taking place in v2 of Turnitin’s iThenticate tool used by members participating in the service. We noted that further enhancements were planned, and want to highlight some changes that are coming very soon. These changes will affect functionality that is used by account administrators, and doesn’t affect the Similarity Reports themselves.
From Wednesday 3 May 2023, administrators of iThenticate v2 accounts will notice some changes to the interface and improvements to the Users, Groups, Integrations, Statistics and Paper Lookup sections.
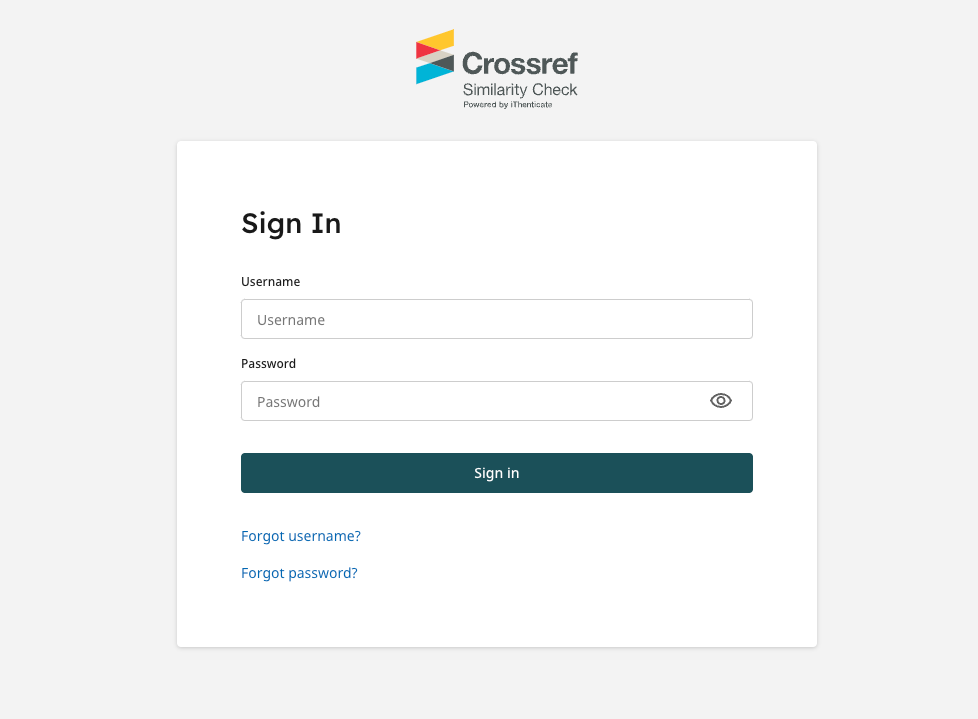
Logging in
iThenticate v2 account administrators and browser users will see a new login page when logging in to iThenticate v2:
A refreshed interface
Once logged in to iThenticate v2, account administrators will see an updated design, with improved notifications to let them know whether a task/action has been successfully completed or not.
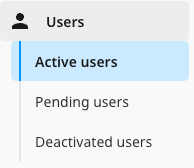
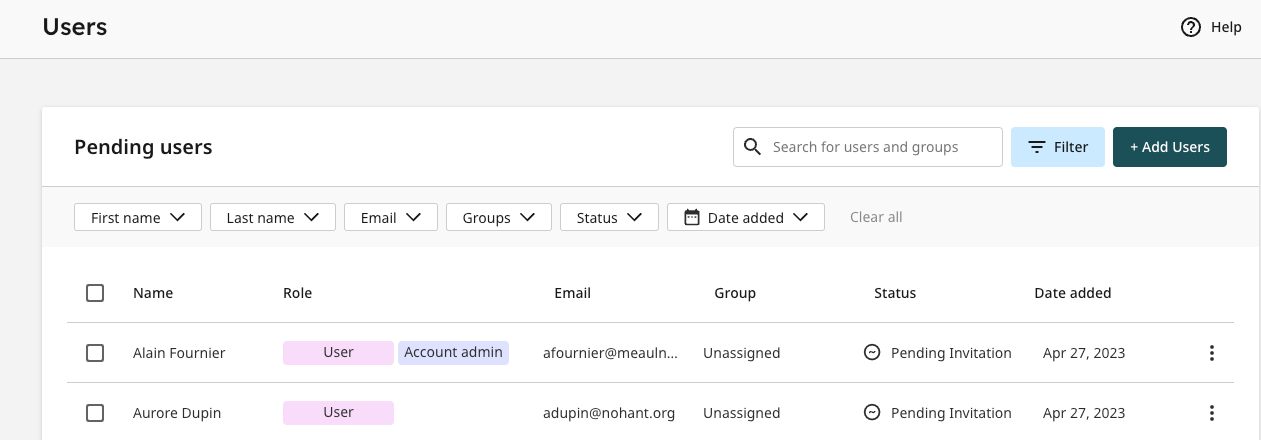
Users
There will be improvements to the user management system for account administrators, including a much clearer navigation menu for managing active, pending and deactivated users.
There will also be a filtering option on the Users page to search for active, pending and deactivated users by first name, last name, email address, group and date added. In addition coloured labels will be introduced to easily identify the level of access (or ‘Role’) for each user.
An improved bulk user import process will be available, with clearer guidance on any issues that may arise during the upload. This new development will also include new screens for adding and editing users with more notifications to help prevent mistakes.
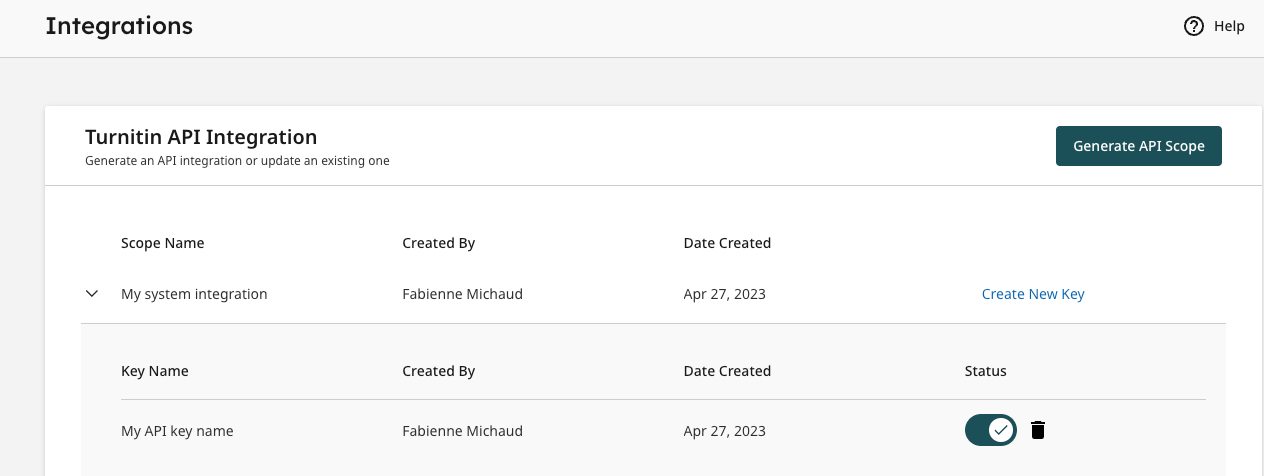
Integrations
For account administrators managing peer review management system integrations and needing to generate API keys, the Integrations page will be improved to make copying API keys simpler.
Statistics
iThenticate v2 administrators will also notice some improvements to the Statistics page. Usage data should load faster and will be sortable by user group. They will also be able to generate large usage reports of over 100k submissions.
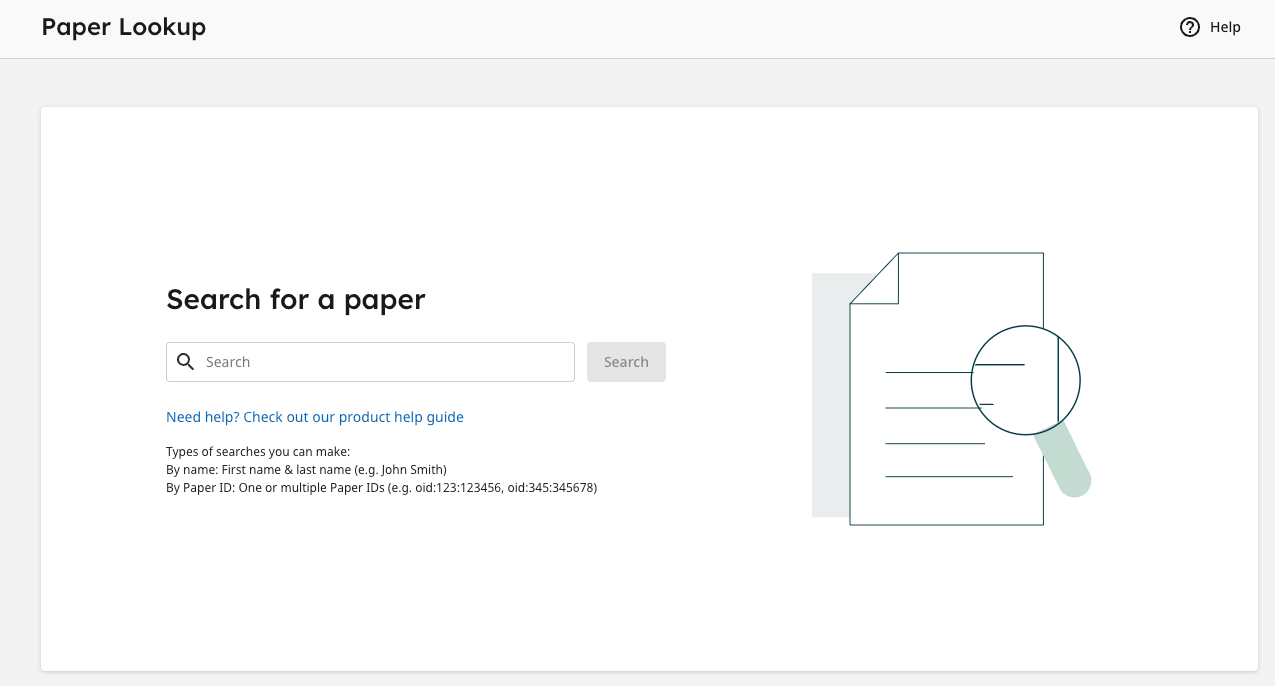
Paper lookup
The Paper lookup will allow iThenticate v2 account administrators to find submissions that have been made from any integration connected to their iThenticate v2 account. They can be found by searching the paper ID (or oid number) of the submission.
Please note: the ability to search for submissions by the user’s name is available for manuscripts submitted via the iThenticate v2 website only and not for papers submitted via an integration.
New password requirements
To improve the security of users’ accounts, new password requirements will be introduced, including a minimum of 8 symbols, 1 special symbol, 1 upper case letter, and 1 number.
Next in iThenticate v2
Turnitin, who produce iThenticate, are currently working on a number of new features and developments including an improved similarity report, paraphrase and AI writing detection. A detailed timeline is not yet available but we’ll be updating you on these new developments in the coming months.
✏️ Do get in touch via support@crossref.org if you have any questions about iThenticate v1 or v2 or start a discussion by commenting on this post below.