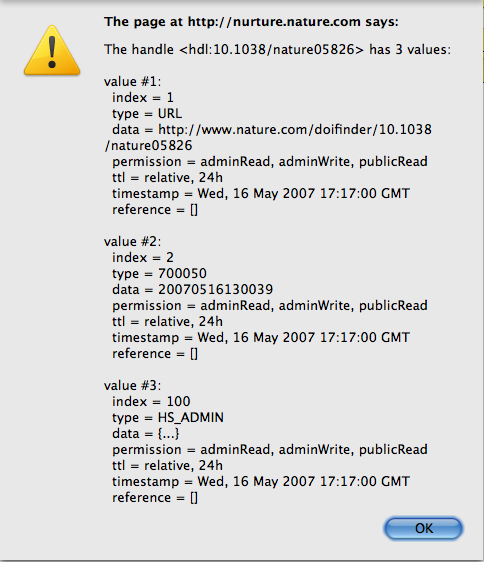
The guidelines for Crossref publishers (“DOI Name Information and Guidelines” - [PDF, 210K][1]) has this to say in “Sect. 6.3 The response page” regarding the response page for a DOI:
“A minimal response page must contain a full bibliographic citation displayed to the user. A response page without bibliographic information should never be presented to a user.”
which would seem to be all fine and dandy. But if that user is a machine (or an agent acting for a user) they’ll likely be out of luck as the metadata in the bibliographic citation is generally targeted at human users.
So here’s a quick and dirty implementation of what a machine readable page could look like using RDFa. (The demo uses Jeni Tennison’s wonderful [rdfQuery][2] plugin which I [blogged][3] about earlier.)
Clicking the DOI link below will bring up in a sub-window a bibliographic citation which might be found in a typical DOI repsonse page. If you now click the “Read Me” link you should see an alert message which presents the bibliographic metadata as a complete RDF document (in a simple N3 – or Notation3 – format). This document is assembled on the fly by rdfQuery using the RDFa markup embedded in the page.
See the “View Source” link to list the actual XHTML markup and the RDFa properties which have been added. And note also that some of the properties are partially “hidden” to the human reader, e.g. a publication date is given in year form only whereas the machine record has the date in full, and some of the properties are fully “hidden”: print and electronic ISSNs, issue number, ending page, etc.
(Continues below.)